First exaFMM paper accepted
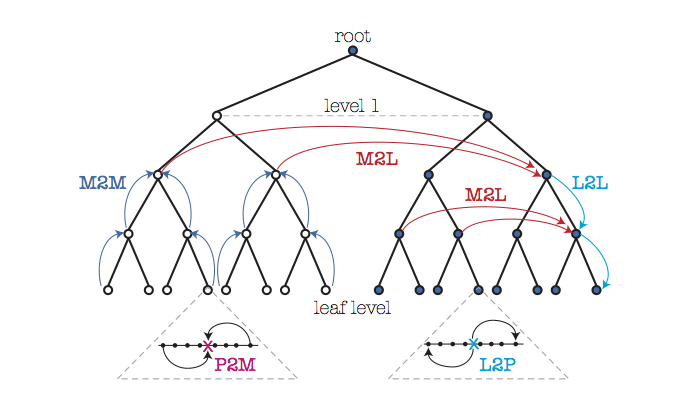
Illustration of the FMM algorithm, with the upward sweep of the tree shown on the left side, and the downward sweep shown on the right side of the tree (Figure 1 of the paper).
The first publication reporting our work towards advancing fast multipole methods (FMM) to be a prime algorithm for exascale systems has been accepted by the International Journal of High-Performance Computing Applications, IJHPCA.
Our previous recent work showed scaling of an FMM on GPU clusters, with problem sizes in the order of billions of unknowns (Yokota et al., 2011). That work led to an extremely parallel FMM scaling to thousands of GPUs or tens of thousands of CPUs.
This new paper reports on a a campaign of performance tuning and scalability studies using multi-core CPUs, on the Kraken supercomputer (Yokota & Barba, 2012).
Intra-node performance optimization was accomplished using OpenMP and tuning of the particle-to-particle kernel using SIMD instructions. Parallel scalability was studied in both strong and weak scaling. The strong-scaling test with 100 million particles achieved 93% parallel efficiency on 2048 processes for the non-SIMD code, and 54% for the SIMD-optimized code (which was still 2x faster).
The largest calculation on 32,768 processes took about 40 seconds to evaluate more than 40 billion unknowns.
This work builds up evidence for our view that FMM is poised to play a leading role in exascale computing, and we end the paper with a discussion of the features that make it a particularly favorable algorithm for the emerging heterogeneous and massively parallel architectural landscape.
IJHPCA is not only one of the top journals in computer science and interdisciplinary applications, but also has an author-friendly copyrights policy and offers paid open-access options.
References
- "Biomolecular electrostatics using a fast multipole BEM on up to 512 GPUs and a billion unknowns", Rio Yokota, J. P. Bardhan, M. G. Knepley, L. A. Barba, T. Hamada. Comput. Phys. Commun., 182(6):1271–1283 (June 2011). 10.1016/j.cpc.2011.02.013 // Preprint arXiv:1007.4591
- "A tuned and scalable fast multipole method as a preeminent algorithm for exascale systems", Rio Yokota, L. A. Barba. Int. J. High-Perf. Comput., 26(4):337–346 (November 2012). 10.1177/1094342011429952 // Preprint arXiv:1106.2176 // Journal website
Published online 24 Jan. 2012