Reproducible and replicable CFD: it's harder than you think
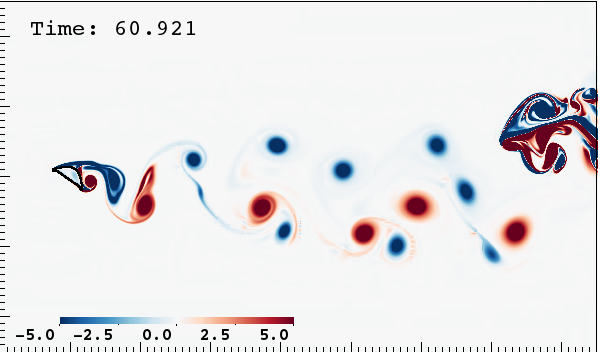
Choosing an incorrect boundary condition with IBAMR resulted in spurious blockage of vortices at the outlet. Thanks to the support received in the code users' forum, this and other problems were resolved and we succeeded in replicating previous findings.
Submitted: 13 May 2016. Preprint arXiv:1605.04339 Accepted: 13 Oct. 2016, Computing in Science and Engineering. Published: 17 Aug. 2017.Overview
We do our best to accomplish reproducible research and have for years worked to improve our practices to achieve this goal. Barba made a pledge in 2012, the “Reproducibility PI Manifesto,” according to which all our research code is under version control and open source, all our data is open, and we publish open pre-prints of all our publications. For the main results in a paper, we prepare file bundles with input and output data, plotting scripts and figure, and deposit them in an open repository. The core of this pledge is releasing the code, the data, and the analysis/visualization scripts. Already this can be time consuming and demanding. Yet, we have come to consider these steps the most basic level of reproducible research.
Recently, on undertaking a full replication study of a previous publication by our own research group (Krishnan et al., 2014), we came to realize how much more rigor is required to achieve this standard, in the context of our science domain (computational fluid dynamics of unsteady flows).
The lessons learned from attempting to replicate our own results were sobering. First, the vigilant practice of reproducible research should go beyond the open sharing of data and code. We now use Python scripts to automate our workflow completely—all scripts are version-controlled, code-documented and accept command-line arguments (to avoid code modification from users). We do not use GUIs for any visualization package. Instead, we call the Python interpreter included in the visualization tools to make all our plots. Throughout, we use Jupyter Notebooks and Markdown files to document partial project advances. Second, certain application scenarios pose special challenges. Our case: unsteady flows dominated by vortex dynamics, is a particularly tough application for reproducibility. Third, extra care is needed when using external code libraries (many scientists rely on linear solvers, for example): they may introduce uncertainties that we can’t control.
In this paper, we distilled the lessons learned from a full replication study of a published work completed by our own group. We used four distinct code bases to study the same problem in aerodynamics: the appearance of a lift-enhancement mechanism at a certain angle of attack for the geometry of a flying snake's body cross-section. Each case brought to the surface challenges that can lead to incorrect results from fluid solvers. Mesh generation, boundary conditions, differences in the external libraries used for solving linear systems: all these aspects can lead to a simulation going awry. We give concrete examples, and end with recommended standards of evidence for computational fluid dynamics, which may apply in other areas of computational physics.
References
- "Reproducible and replicable CFD: it's harder than you think", Olivier Mesnard, Lorena A. Barba. IEEE/AIP Computing in Science and Engineering, 19(4):44–55 (August 2017). 10.1109/MCSE.2017.3151254 // Preprint arXiv:1605.04339 // Authorea manuscript // GitHub repo
Accepted October 2016.
- "Lift and wakes of flying snakes", Anush Krishnan, John J. Socha, Pavlos V. Vlachos, L. A. Barba. Phys. Fluids, 26:031901 (2014). 10.1063/1.4866444 // Preprint arXiv:1309.2969 // figshare: body geometry // figshare: lift and drag coefficient curves //
- "Reproducibility PI Manifesto", L. A. Barba. (13 December 2012). 10.6084/m9.figshare.104539
Presentation for a talk given at the ICERM workshop “Reproducibility in Computational and Experimental Mathematics”. Published on figshare under CC-BY.